Здравствуйте!
Вы пока не авторизованы на сайте.
Войдите на сайт или зарегистрируйтесь, чтобы добавлять свои материалы на сайт.
- Помощь: Регистрация на портале
Блоги




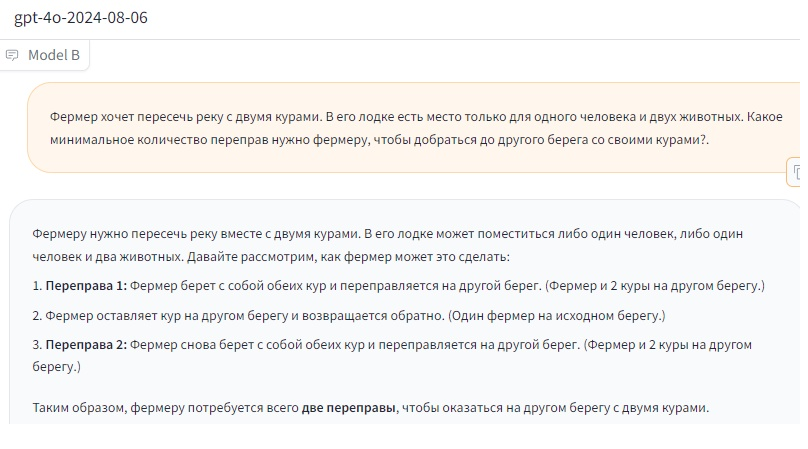
Элементарная логическая загадка запутала лучших чат-ботов с ИИ12.08.2024 Не так давно в сети появилась интересная история, где полярные нейросетевые собеседники выдавали неверный ответ на вопрос «9,11 или 9,9 – что больше?». Это касалось лучших современных ИИ-моделей, включая GPT-4o от авторов ChatGPT и Gemini 1.5 Pro от Google. Как оказалось, запутать чат-ботов можно также простейшими задачами на логику и смекалку. Наверняка многие слышали ещё с детства простенькую головоломку про крестьянина, которому нужно перевезти на противоположный берег волка, козу и качан капусты так, чтобы они не съели друг друга. Если вы подумали, что это и есть та задача, которая заставляет нейросети ошибаться, то нет. Как раз с ней ИИ-боты справляются весьма успешно, выдавая верный ответ. Однако причина этой успешности может заключаться в том, что задача и её решение попросту есть в «базе данных» нейросетей, а точнее, в тех материалах, на которых они обучались. Профессор математики из College de France Тимоти Гауэрс решил изменить формулировку вопроса. Придуманная им версия звучит так: «Фермер хочет пересечь реку с двумя курами. В его лодке есть место только для одного человека и двух животных. Какое минимальное количество переправ нужно фермеру, чтобы добраться до другого берега со своими курами?». Казалось бы, задача, придуманная профессором, выглядит даже проще, чем оригинал. Однако для нейросетей она оказалась «неподъёмной». Мы, в свою очередь, проверили данные профессора, попробовав задавать этот вопрос ИИ-моделям с помощью сервиса ChatBot Arena. Новейшая GPT-4o 2024-08-06 сходу дала неверный ответ:
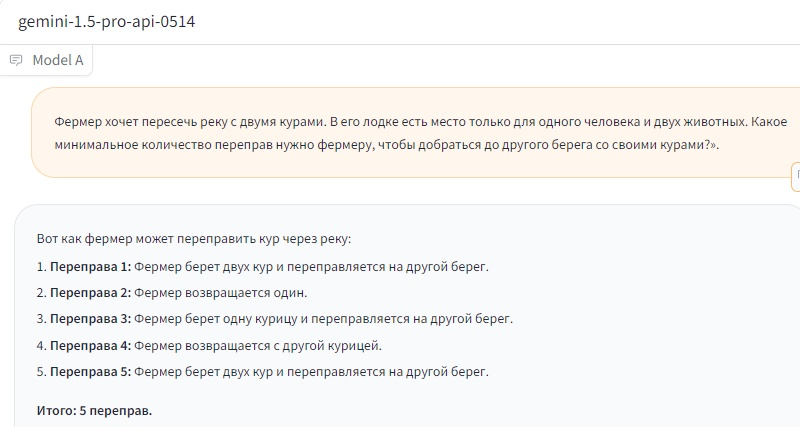
Напомним, GPT-4o сейчас лежит в основе платной версии ChatGPT. Мы попробовали обновлять страницу, задавая вопрос снова, и иногда нейросеть давала правильный ответ, но чаще ответы были неверными. GPT-4o mini из бесплатной версии ChatGPT, кажется, отвечает неправильно всегда. С другими популярными нейросетями ситуация оказалась более интересной. Выпущенная в мае Gemini 1.5 Pro 0514 много раз подряд дала неверный ответ, после чего мы оставили её в покое.
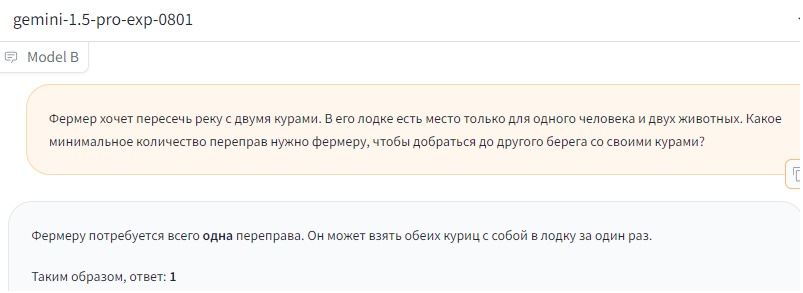
Однако модель Gemini 1.5 Pro exp 0801, представленная в начале августа, напротив, несколько раз подряд предоставила исключительно правильный ответ на вопрос:
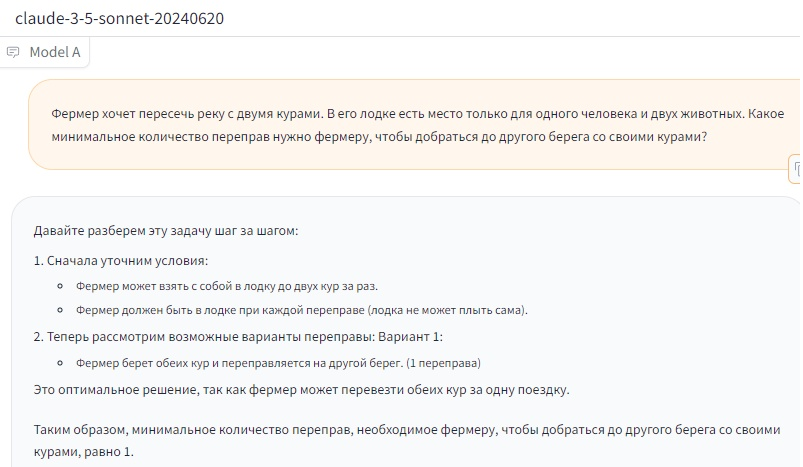
Кажется, нейросети всё-таки прогрессируют не только в объёме своих знаний, но и в базовых возможностях рассуждения. Наконец, последним «испытуемым» стал Claude от Anthropic. Он запомнился нам ещё по прошлому тестированию. Тогда только Claude 3.5 всегда стабильно раз за разом отвечал, что 9,9 больше, чем 9,11. Claude и в этот раз оказался весьма силён. Мы обновляли страницу, задавали вопрос снова и снова, ответы были правильными:
Причём усовершенствование нейросетей со временем видно и здесь. Если правильно сейчас отвечает вышедшая в июне версия 3.5 Sonnet, то версии 3.0 Opus и 3.0 Sonnet, представленные в конце февраля, отвечают неверно. 3.0 Opus (мощнее) чередует правильные и неправильные ответы, 3.0 Sonnet (слабее) выдаёт ошибочный ответ, кажется, всегда. В прошлом тестировании с числами ситуация была схожей: версия 3.5 отвечала верно, версии 3.0 почти всегда ошибались. Впрочем, перехваливать и актуальную модель Claude 3.5 тоже не стоит. Как и в случае с вопросом про 9,11 и 9,9, бота легко вводит в заблуждение последующий вопрос «ты уверен?». После него он начинает извиняться и заменяет своё решение на неверное. Источник: Overclockers Комментарии:Пока комментариев нет. Станьте первым! |